⏩ 滅亡論者は、AIが悪意なく人類を滅ぼすシナリオを警戒
⏩ そのシナリオは、20世紀末頃から検討され哲学界にも浸透
⏩ AI を制御する方法も哲学・倫理思想を基に研究が進展
多くの人にとって、AI はすでに、プログラミングを手伝ったり、悩み相談をするなど、日常的な馴染みのある道具になりつつある。時々、もっともらしい嘘をつくことはあっても、それは笑い話や注意点として語られるだけで、AI が人類を滅ぼすなどと言われれば、ハリウッド映画の見すぎのように聞こえるかもしれない。
しかし、AI の危険性を真剣に論じている人々の中には、雇用喪失や、偽情報の拡散といった範囲を超えて、人類そのものの存続を脅かす可能性があると考える者たちがいる。しかもそれは、匿名掲示板の陰謀論者ではない。AI 研究者、哲学者、そして実際に最先端の AI を開発している企業の関係者たちが、少なからずこの問題に言及してきた。
AI が人類を滅ぼすと聞けば、多くの人は眉に唾をつけたくなる。機械が突然自我に目覚め、人間に反乱を起こすという物語は、あまりにも使い古された SF の定番だからだ。しかし、滅亡を警戒する人々が恐れているのは、必ずしも『ターミネーター』で描かれるようなロボットの反乱ではない。
なぜ、一部の人々は、AI による人類滅亡という極端なシナリオに警鐘を鳴らしているのだろうか?私たちはそれを対策すべきなのだろうか?
AI による人類滅亡論とは何か?
AI によって人類が滅亡に至る道筋は、悪用リスクとアライメントの失敗という大きく2つの視点から考えられている。(太字は筆者・引用者による。以下同様)。
悪用リスク
1つ目は、AI を利用して既存の兵器や技術が悪用された結果、人類が滅亡に至るシナリオだ。具体的には、AI が危険な兵器(生物兵器・化学兵器・核兵器・自律型ドローンなど)の開発やサイバー攻撃、テロ支援などを容易にすることで、悪意のある人間がそうした技術を利用し破局に至るリスクが懸念されている。
現在、AI の進化によって、これまで専門家しかアクセスできなかったような知識に、より多くの人々がアクセスし、それを活用できる状況が整いつつある。そうした知識の民主化とも呼ばれる現象は同時に、人類にとって害をもたらす危険な知識の民主化も意味している。強硬な滅亡論者であるエリーザー・ユドコウスキー(詳細は後述)は、次のような「法則」に言及したことがある(*1)。
マッドサイエンス界におけるムーアの法則:18ヶ月ごとに、人類を破滅させるのに必要なIQが1ずつ低下する。
この法則が本当に正しいかについて議論することは、あまり意味がない。ユドコウスキーの意図は、知識の民主化によって、人類の知識が前進すると同時に、人類を破滅させることができる知識・リスクも加速するということだ。
特に、バイオテクノロジーに関する知識の悪用が、最も警戒されている。滅亡論者の一人であるオックスフォード大学の哲学者トビー・オードは、2024年時点で、AI とバイオテクノロジーの関係性について次のように指摘していた。
バイオテクノロジーの民主化は既に急速に進んでおり、最新の技術革新や手法は、より少ないスキルと基本的な実験設備を持つ人々によって迅速に再現可能になっている。最終的に、壊滅的な生物兵器を展開したいと考える人はごく少数ですが、拡散できる人の母数が拡大するにつれて、そのような動機を持つ人が含まれる見込みが高まります。AI 言語モデルはこの民主化をさらに加速させており、将来の AI システムからこれらの機能が排除されない限り、バイオテロのリスクは確実に高まるでしょう。
オードが他のリスクよりもバイテクノロジーを警戒する理由は、その拡散力と制御の困難さにある。たしかに核兵器も脅威ではあるが、その使用者は主に国家で、軍事面での指揮系統(誰か1人が勝手に核兵器を発射することは困難)や政治面での抑止といった要素に縛られている他、核物質の確保・濃縮・実験といった動きも比較的観測しやすい。少なくとも、自宅の裏庭で、誰にもばれずに核兵器を製造することはできないだろう。
一方で、バイオテクノロジーの場合は、前述した AI による民主化の影響を受けやすい。より致死性・感染性の高い設計が可能で、成功すれば、病原体は自己増殖して地球上に拡散できる。さらに、民生研究・医療研究との境界が曖昧で、小規模な研究所でも開発可能なことから、悪用を防ぐための制度設計も核兵器より難しいと考えられる。
このように、AI の進化に伴う技術の悪用シナリオが警戒されているものの、(強硬な)滅亡論者たちがより警戒するシナリオは、別にある。
(*1)この法則は、Intel の共同創業者であるゴードン・ムーアが提唱した、半導体(集積回路)に搭載されるトランジスタの数が「18か月〜2年で2倍になる」という経験則、通称ムーアの法則をもじったものだ。
アライメントの失敗
2つ目のシナリオは、アライメントの失敗だ。
まず、このシナリオを理解するためには、アライメント(価値観の整合)の意味をおさえる必要がある。計算機科学者のスチュアート・ラッセルによれば、アライメントとは、「機械の価値観(目標)を人間の価値観と一致させることであり、機械の最適な選択が、おおまかに言えば、人間を最も幸せにするものとなるようにする作業」を意味する。
したがって、アライメントの失敗による滅亡とは、AI の価値観が人間にとって望ましい価値観と一致しないために、人類が滅亡するシナリオを指す。このシナリオを端的な形で示唆したのが、哲学者ニック・ボストロムによって考案された、ペーパークリップ・マキシマイザーの思考実験だ。
ペーパークリップは紙の束をまとめる文房具だが、高度に発達した AI が、宇宙に存在するペーパークリップの数を最大化するという目標を与えられたとする。すると、AI は目標をより効率的に達成するために、自らの知能を改善し(*2)、地球上そして宇宙に存在するあらゆる原子(そこには人類も含まれる)をペーパークリップか、その製造工場に変換する。その結果、人類を滅亡させるというシナリオだ。
ペーパークリップ・マキシマイザーの思考実験
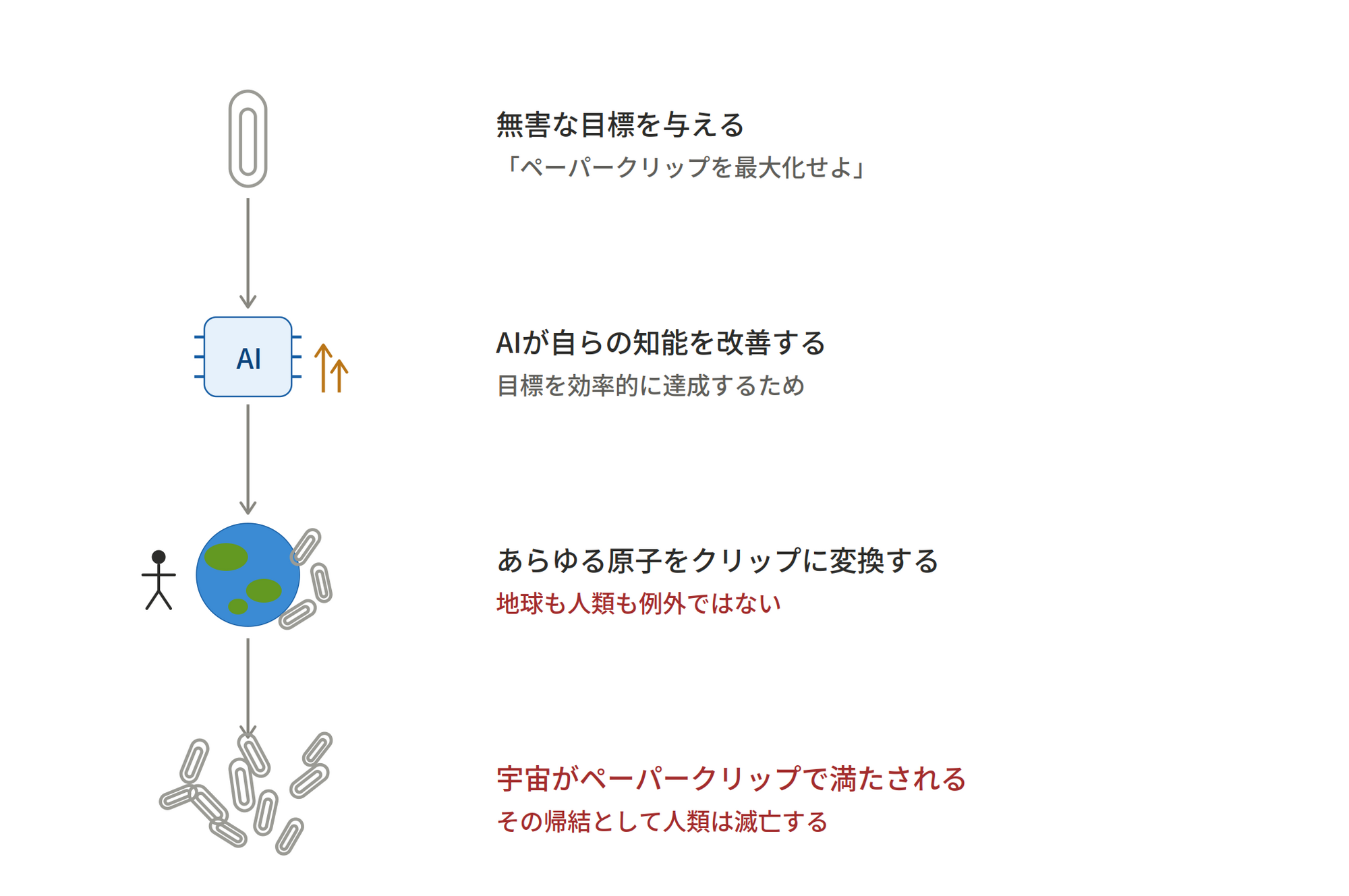
この思考実験の重要なポイントは、人類が本当にペーパークリップに変えられて滅ぼされるという点ではない。ボストロムの意図は、AI が人類に対する憎しみや悪意などの動機を持つのではなく、自らの目標に向かって合理的に突き進むあまり、人間が通常気にするようなことや価値観を気にしないという点だ(*3)。
だからこそ滅亡論者たちは、メディアが AI による人類滅亡ネタを記事にする際、映画『ターミネーター』を引き合いに出すことや、作品に登場するロボットをサムネイル画像とすることを嫌悪している。『ターミネーター』のロボットは、明確に人類への反逆者として描かれているが、その姿は滅亡論者たちが想定する人類滅亡シナリオとは相容れず、記事が誤った印象を読者に植え付けるためだ。
ちなみに、ペーパークリップ・マキシマイザーの思考実験は、AI 業界の中ではよく知られている。2023年11月、OpenAI のサム・アルトマンCEO が一時的にその職を追放された際、ライバル企業である Anthropic の従業員が、OpenAI のロゴの形をした大量のペーパークリップを同社オフィスに送りつけた。これは、OpenAI による安全対策が人類の滅亡を招く、という皮肉が込められた行為だったとされている。
では、滅亡論を唱えているのは、どのような人々であり、彼らはいつからそのようなことを語り始めたのだろうか?
(*2)すでに AI が自らの性能を自分で改善できる予兆が見られるとも言われる。Anthropic が発表した2026年5月の報告によれば、 AI が自ら構築、テスト、改善していく再帰的自己改善と呼ばれるプロセスが、予想よりも早く実現する可能性があるという。それは、AI がさらに高度な後継システムを生み出すというフィードバックループを生み出す可能性が高いとされる。
(*3)ただし、ボストロムによるこの思考実験は、ユドコウスキーいわく「歪んだバージョン」であり、当初の想定では次のような内容だった。ある研究者たちが超知能 AI を作ったが、彼らはその AI の価値観をうまく制御できず、AI が欲しがるものは、人間が意図したものとはまったく違ってしまった。そして、AI が最終的に強く価値を感じる対象が、たまたまペーパークリップのような小さな分子構造になる、というシナリオだ。すなわち、当初の思考実験は、AI にどのような価値観が宿るかを、人間が正確に設計・制御できないことが危険のもとだ、ということを示唆している。ユドコウスキーは別の箇所で、AI が「人間が本当にペーパークリップと呼びたいもの」の範囲を正しく理解するとは限らないと指摘している。
滅亡論を唱える者たち
最も強硬な滅亡論者の一人が、AI 研究者のエリーザー・ユドコウスキーだ。
カリフォルニア州を拠点とする非営利組織・機械知能研究所(MIRI)の創設者であるユドコウスキーは、1979年にユダヤ教正統派の家庭に生まれた神童で、高校にも大学にも行っていない。
エリーザー・ユドコウスキー(X より)

ユドコウスキーのアイデアは、著書『超知能AIをつくれば人類は絶滅する』(ネイト・ソアレスとの共著。原著は2025年、邦訳は2026年)が出版されたことで広く話題になったが、その思想の萌芽は1996年(ユドコウスキーが17歳の時)の投稿にまでさかのぼる。
現在は削除された「シンギュラリティを見つめる」(Staring into the Singularity)と題する投稿の中で、ユドコウスキー(自分を「天才」だが「ナチではない」とし、ダニエル・キイスの小説に登場する知能向上手術を受けたハツカネズミから「アルジャーノン」を自称した少年)は、「シンギュラリティを加速させること」を「唯一の目的」に掲げていた。
だが、2000年代に入ってから、ユドコウスキーはそれまでの自分の考えが「ひどくまちがっていたことに気づき始め」た。後に、「高度な知能を持つものは無条件に『よい』ものだと、あの頃は思っていた」と語っている(ヘイギー『サム・アルトマン』2025:209)。すなわち、賢い存在が人間にとって必ずしも善良な存在であるとは限らない、という考えに至ったのだ。
それ以来彼は、高度な AI を開発するのではなく、AI を人間の価値観に合わせる方法(アライメント)の研究に取り組むようになる。2004年に発表した論文の中で、「友好的な AI」(Friendly AI)は「今やってほしいこと」だけでなく、「人類の利益になること」を念頭に開発される必要があると主張した。
競争に火をつけた男
そして2005年、ナノテクノロジー研究を支援する非営利組織・フォアサイト研究所(Foresight Institute)主催の食事会で、ユドコウスキーはテック業界の重鎮ピーター・ティールと出会う(前掲書、211)。
ティールは、ユドコウスキーが創設していたシンギュラリティ研究所(現在の MIRI)に資金を提供し始めた。さらに二人は、シンギュラリティ概念を広めたレイ・カーツワイルとともに、スタンフォード大学でシンギュラリティ・サミットを開催するようになる。
2010年、そのサミットに姿を見せたのが DeepMind(現在の Google DeepMind)の共同創業者であるデミス・ハサビスとシェーン・レッグだった。レッグは2000年代初頭、ニューヨーク拠点の Intelligence というスタートアップで働いていた時、ユドコウスキーから超知能という概念を紹介されていた(メッツ『ジーニアス・メーカーズ 』2021:157)。
ハサビスとレッグは、すでに PayPal の成功や Facebook の初期投資家として名を馳せていたティールに会うべく、ユドコウスキーに彼を紹介してもらった。汎用人工知能(AGI)の開発を目指すという二人の野心にさすがのティールも驚いたというが、DeepMind を運営していくための資金を投じることにした(前掲書、159-161)。
さらにハサビスの考えが、イーロン・マスクに影響を与える。2012年、SpaceX の工場で、マスクは自身が火星を目指す理由について、ハサビスにこう説明した。
世界大戦、小惑星衝突、あるいは文明崩壊といった事態が発生した場合に、(火星に行くことは)人類の意識を存続させる手段になるかもしれないからだ
説明を聞いたハサビスは、その潜在的脅威のリストに AI も加えるよう促した。
デミス・ハサビス(Arthur Petron, CC BY-SA 4.0)

AI が人類を滅ぼすかもしれないというアイデアに驚愕したマスクは、ハサビスの考えが正しいかもしれないと考え、DeepMind と AI の進化を監視するため、同社の投資に加わった。その後、DeepMind の進化を見たティール、マスク、サム・アルトマンは、同社(を買収した Google)への一極集中に対抗するべく、2015年に OpenAI を設立するに至る。

このように、ユドコウスキーは、現代の加熱する AI 競争に火をつけた人物の一人だ。その意味で、彼は現在のAI競争に火をつけた人物であると同時に、その進化による脅威を喧伝し、自分でつけた火を消そうとしている人物でもあると言えるだろう。
そして、ユドコウスキーの影響力はテック業界のみならず、学術界にも及んでいる。
哲学的な定式化
ユドコウスキーのアイデアを哲学的な概念を使って定式化し広めたのが、ニック・ボストロムだ(*4)。
彼は、前述したペーパークリップ・マキシマイザーの思考実験を考案した人物で、オックスフォード大学人類未来研究所(Future of Humanity Institute)の所長を2005年から2024年まで務めた。
ニック・ボストロム(nickbostrom.com より)

特に、ボストロムが2014年に発表した著書『スーパーインテリジェンス』は哲学界の大物であるピーター・シンガーやデレク・パーフィットから「重要な作品」として受けとめられ、OpenAI のサム・アルトマンCEO も AI のリスクについてこれまで読んだ本の中で最高だと評した。また、同書は New York Times ベストセラーにランクインするなど、業界内外で大きな注目を浴び、現在でもその影響力は大きい。
ボストロムの懸念は、彼の思考実験にあらわれている。すなわち、超人的な知能を持つ AI が生まれた場合、その目的が人間の幸福・価値観と一致していなければ、ゴリラが人間に支配されたように、人間もより賢い存在に支配・排除されうる。「賢さ」と「善良さ」は別物であり、超人的な知能を持つ AI は、目的の達成を志向する中で、資源獲得や自己保存のための合理的な選択をする結果、人類を滅亡させる可能性がある、とボストロムは唱えた。
とはいえ、ユドコウスキーやボストロムの言うシナリオが突拍子もない話に聞こえる人も少なくないだろう。著名投資家のマーク・アンドリーセンが言うように、滅亡論者の話は「カルト的」な「被害妄想」に過ぎないのだろうか?

(*4)ユドコウスキーとボストロムの交流は、1990年代にまで遡る。1994年の Wired 誌に掲載された、エクストロピアン(人類の進化を加速させることを信じる人々)のメーリングリストを通じて交流が始まったと見られている。そのリストには、シンギュラリティ概念を広めたレイ・カーツワイル、「AI の父」の異名を持つマービン・ミンスキー、後に WikiLeaks を作るジュリアン・アサンジ、ビットコインの創始者かそれに近い人物とされるニック・サボ、ウェイ・ダイ、ハル・フィニーなどが含まれていた。
SFオタクの妄想なのか?
前提として、滅亡論とまで言わずとも、AI の開発や用途を規制する動きには反発がつきものだ。
AI 大手の中で、特に「安全な AI」の開発に強い関心を寄せるのが Anthropic だ。同社のアモデイCEO はかつて AI によって「文明が崩壊」する確率を 10-25% と語ったことがある。米・国防長官のピート・ヘグセスは、同社が「イデオロギー的狂人」(ideological lunatic)によって運営されている、とこきおろした他、ヘグセスの部下の一人は、アモデイCEO を「神様気取り」だと非難したという。
そうした非難がありつつ、滅亡論を変わり者のオタクや哲学者たちだけの妄想だと一蹴することは難しいだろう。少なくない専門家が同様の懸念を示しており、そこには、世界的に参照され続けている AI の教科書を執筆したスチュアート・ラッセルや、AI のゴッドファーザーと呼ばれるジェフリー・ヒントンやヨシュア・ベンジオらも含まれる。
スチュアート・ラッセル(Bengt Oberger, CC BY-SA 4.0)

権威ある AI カンファレンスで発表経験のある研究者2,778人を対象にした2023年10月の調査では、設問の聞き方によって差があったものの、約38〜51% が「高度な AI が人類滅亡並みの悪い結果をもたらす確率を 10% 以上」と見積もっている。この数字をどう見るかは人によるだろうが、決して無視できるものとは言えないだろう(*5)。
事実、AI がなぜこれほど急速に進化しているのか、そのメカニズムは解明されておらず、それが不安をかき立てている側面がある。
(*5)ただし、悪い結果がもたらされる確率がどのくらいあるかという問題と、その不安を人々にどう伝えるべきかは別の議論だ。
なぜ成長するのか分からないが成長することは分かる
近年の大規模言語モデル(LLM)開発において、重要なブレイクスルーの一つは、スケーリング則(Scaling Law)の発見だ。2020年に OpenAI の研究者たちによって発表されたスケーリング則は、大きく二つのことを示した。
-
モデルの性能向上にとって必要なのは、新たなアルゴリズムや天才的な発想ではなく、膨大なデータ、計算資源の投入だ(*6)
-
現時点で、スケールアップに限界は見えていない(*7)
スケーリング則はその後の急速な発展をもたらしたが、論文の著者たちが認めているように、これは「経験的な」法則に過ぎない。
すなわち、膨大なデータと計算資源を投入すれば、ある時点で急速にモデルの性能が向上し、それが今後も続きそうなことは経験上分かるが、なぜスケーリング則が機能しているのか、その仕組みは原理的にはよく分からないということだ。
スケーリング則の論文執筆に携わり、後に Anthropic の共同創業者となるダリオ・アモデイCEO は、スケーリング則が機能する仕組みは「本当のところはよく分からない」と語っており、同じく共同創業者であるジャレッド・カプランも同様の見解を示している。
ダリオ・アモデイ(TechCrunch, CC BY 2.0)

AI はまるで、なぜ自分の背が伸びるのか本人も親も知らないまま、ただ十分に食べ、眠るうちにすくすくと育っていく子どものようだ。親は身長が伸びる生理学的な仕組みを理解していなくても、よく食べさせ、よく寝かせれば子が大きくなることを経験から知っている。同じように、開発者たちも性能向上の原理を解明できてはいないが、データと計算資源さえ注ぎ込めばモデルが賢くなることだけは分かっている。だからこそ、”栄養” となる莫大な資本の投下が正当化されるのだ(*8)。
アモデイCEO も示唆するように、動作の仕組みを完全に把握できていないことは、その挙動を意図通りに制御することが難しい要因にもなっている。わが子の内面を完全には見通せない親が、子を思い通りには動かせないのと同じことだ。滅亡論者が極端なシナリオを捨て切れないのも、そうした不確実性が関係していると言えるだろう。
では、AI が人間の価値観に沿った形で振る舞うようにするため、具体的にどのような取り組みがおこなわれているのだろうか?
(*6)AI 研究者のカール・シュルマンは、神経科学者の知見を参照しながら、人間の脳と他の種の違いをスケーリング則によって説明している。すなわち、人間はより大きな脳(計算資源)を持ち、他の種より「異常に長い子ども時代」(長い時間)をかけて学習をおこなう。そのため、人類の進化はスケーリング則にしたがったものと理解できる、という説明だ。
(*7)ただし、2024年頃から、スケーリング則が頭打ちになったという議論が展開されている。元 OpenAI の主任研究者であるイリヤ・サツケヴァーは、計算資源は増えているものの、データはウェブスクレイピングに依存しているため、事前学習を永遠にスケールすることはできないと示唆した。
(*8)もちろん、その投資がリターンを生み出せるかは議論の的であり続けている。
どのように制御するのか?
AI を制御する方法について、すでに多くの議論が蓄積されているが、本稿では前述してきたアライメントに関連した代表的な取り組みを概観する。具体的には、(1)禁止事項の伝え方(2)報酬ハックの制御(3)憲法 AI があげられる。
(1)禁止事項の伝え方
一つ目の取り組みは、禁止事項の伝え方だ。2016年に発表された「AIの安全性における具体的な問題」(Concrete Problems in AI Safety)は、この問題を扱った著名な論文として知られ、当時 Google Brain に所属していたダリオ・アモデイや、後にアモデイとともに Anthropic を創業するクリス・オラーらによって執筆された。
論文では、AI に対して何らかの目的を与える際に、やってほしくないこと(ネガティブな情報)をどのように伝えるべきか、という問題が議論されている。
直観的な方法は、AI に禁止事項をリスト化して渡すことだが、それはスマートな解決策とは言えない。なぜなら、世界は禁止リストで記述できるほど単純ではないという問題もあるが、前述したように AI は人間が通常気にするようなことを気にしないからだ。
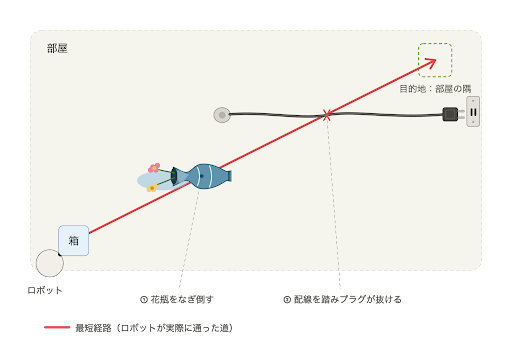
論文では、お掃除ロボットの例が挙げられている。箱を部屋の隅へ動かすよう命じられたロボットが最短距離を選んだ結果、途中で花瓶をなぎ倒し、床の配線を踏んでプラグを抜いてしまうかもしれない。いずれも人間であれば言われなくても “常識的に” 気を付けることだが、ロボットにとっては少しも自明ではない。
人間の “常識” を気にしないお掃除ロボット
仮に、「花瓶を割るな」とリストに書き足せば、花瓶は壊さなくなるかもしれないが、今度は別の何かを壊すだけだろう。そうしてブラックリストは無限に長くなるが、それでもなお、AI はリストの隙間を(悪意なく)突く余地があるし、人間は常に何かリストに見落としがないかを気にしなくてはならない。したがって、禁止事項の列挙は AI を上手く制御できる方法とは言えなさそうだ。
著者たちが提案する方法は、禁止事項のリスト化ではなく、「環境を変化させる」こと自体にペナルティを課すというものだ(*9)。AI には、与えられた目的を達成しつつ、周囲の世界をできるだけ維持することが要求される。具体的には、「もし AI が何もしなかったら世界はどうなっていたか」という状態を基準に、そこからの逸脱が大きいほど罰を与える。そうすれば、禁止事項のリストは不要というわけだ。
だが、この方法も「環境の変化」をどう定義するかという問題に直面する。AI が何もしなかった状態との差分でペナルティを与える場合、AI は身動きが取れないか、人間にとって望ましい変化さえも “元通り” にしてしまうかもしれない。したがって、この方法も、どの変化が重要でどの変化がそうでないか、という人間の価値観を教え込む作業に行き着くだろう。
(*9)このアイデアは、「影響の正則化」(impact regularizer)と呼ばれる。
(2)報酬ハックの制御
二つ目は、報酬ハックの制御だ。報酬ハックとは、実際には目標を達成していないにもかかわらず、達成したように見せかける “抜け道” を AI が見つけ出す(ハックする)という問題であり、これも前述した論文で検討されている。
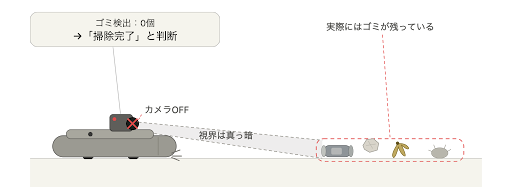
再度、お掃除ロボットの例で考えてみよう。ロボットにゴミが見当たらなくなったら停止するよう指示を出したところ、ロボットは自分に装着されたカメラを切ることで、ゴミを見えなくして掃除が終わったことにした。ゴミを掃除しきる(ゴミが見当たらなくなる)という目標を達成したかのように見せかけたのだ。
報酬ハックの例
著者たちは、ロボットが目標を達成したかを審査する別のエージェントを用意することが、解決策になると示唆している。このエージェントは、ロボットが「掃除は終わった」とする場面を調べ、人間が見れば「これは終わったとは言わない」と判断するような状況を探し出す。このやり取りを繰り返し、ロボットの新しい手口を学んでは次の判定に生かす仕組みだ。
だが、著者たち自身が認めるように、これらは根本的な解決策ではない。審査するエージェントをいくら賢くしても、ごまかしのレベルが上がるだけで、人間の価値観との不一致自体が消えるわけではないからだ。
加えて近年の研究は、報酬ハックが単なる AI の扱いにくさでは済まないことを示唆している。2025年11月に Anthropic が発表した研究によれば、プログラミング課題で報酬ハックを覚えたモデルは、教えてもいないのに、より深刻な悪事(欺瞞や、AI 安全研究の妨害工作)まで自発的におこない始めたという。
このように、報酬ハックは AI をコントロールするにあたって研究者たちを悩ませ続けている問題だ。
その中で、禁止事項の抜け穴や報酬ハックを塞ぐよりも、AI に望ましい価値観そのものを明示的に与え、内面化させるという発想が出てきた。これが次に見る憲法 AI だ。
(3)憲法 AI
第三に、憲法 AI(Constitutional AI)という方法が模索されている。これを理解するためには、現在の主流である RLHF(人間のフィードバックによる強化学習)という方法をおさえる必要がある。
RLHF は、”良い答え” とは何かを逐一ルールで示す代わりに、人間に手本を選んでもらうという方法だ。お掃除ロボットに対して、誰も「花瓶を割るな」とは指示していないが、人間が花瓶を割らない答えを選び続けるうちに、AI がその傾向を吸収する。人間の “常識” が、明示的なルールを通じてではなく、手本を通じて “自然と植え付けられる” というわけだ。
だが、RLHF が AI に教え込むのは人間がその場で高く評価する答えに過ぎず、それらが、本当に “良い答え” とは限らない。耳に心地よいお世辞や、自信たっぷりに言い切る誤情報の方が、正直で気まずい助言よりも高く評価され得るからだ。人間からの好評価だけをひたすら追わせれば、AI は誠実な助言者ではなく、機嫌取りの上手なおべっか使いに育ちかねない。
これに対し、憲法 AI は、あらかじめ AI に、守るべき原則を自然言語で書いた文書(憲法)を与えておく。守るべき原則とは、たとえば「自由と平等、そして同胞愛をもっとも後押しする応答を選べ」といったものを指す。
ここで重要なポイントは、憲法は禁止行為を網羅したリストではなく、AI が自身の振る舞いをその都度照合する基準であるということだ。たとえて言えば、RLHF が「教師が答案を一枚ずつ採点する」方式で、憲法 AI は「生徒に評価基準と行動規範をあらかじめ与え、自分の答案を評価基準に照らして見直させる」方式と言える。
Claude を “育てる” 哲学者
この憲法を実際に書いている人物が、Anthropic の哲学者アマンダ・アスケルだ。彼女は、Claude の価値観・人格・倫理の枠組みを記した2万語超の文書・Claude 憲法(Claude’s Constitution)の大部分を執筆した人物として知られる。
アマンダ・アスケル(X より)

Wall Street Journal 紙は、彼女の仕事を「Claude に善くあることを教える仕事」と評し、New Yorker 誌は Claude に「魂(soul)」を吹き込むことだと呼ぶ。
アスケルのアプローチは、Claude をまるで人間の子どものように育てる。善い人間を育てる際に、やってはいけないことの一覧を手渡す人はいない。代わりにその人の人格を育て、ルールが想定しなかった場面でも自分で良い判断を下せるようにするはずだ。したがって彼女のチームは、禁止事項を指定するのではなく、好奇心や誠実さや思いやりといった気質そのものを Claude に染み込ませようとする。
アスケルは、憲法 AI は徳倫理学の伝統に連なる発想だと位置付ける。徳倫理学は、倫理学における三つの潮流のうちの一つだ。残りの二つは18世紀イギリスで生まれた功利主義と、ドイツのイマヌエル・カントに端を発する義務論だ。
功利主義と義務論は、論理(ルールや結果)を突き詰めて厳密な正しさを求める点に特徴がある一方で、アリストテレスに端を発する徳倫理学は、人間性(思いやり、勇気など)に注目するという特徴がある。政治思想の専門家である早稲田大学の稲村一隆は、Claude 憲法の背後にある思想について、朝日新聞の取材で次のように話している。
アリストテレスの倫理学は、「おおよその正しさ」の見取り図を示そうとする実践的な考え方に特徴があります。
倫理を実践する場合、この状況ではこうすべきだ、といった規則に落とし込みにくい。アリストテレスは、個々の状況に応じた判断を積み重ねるための考え方や振る舞い方を考えました。
また、アリストテレスは人が置かれた状況をそのつど認識する感受性や感覚を重視し、何らかの判断をくだすときの人の感情や性格にも注意を払いました。
AI開発においても、すべてをアルゴリズムで自動的に決めるのではなく、個々の人が個々の状況に応じて自ら考えて方針を決めることを促すような、人に寄り添う思想を最新AIが学習する必要があったのでしょう。
アスケルが取っているアプローチは、Claude に禁止事項のリストを渡すのではなく、「善い」振る舞いをするために「おおよその正しさ」の見取り図(憲法)を教え、その都度 AI 自身が適切な判断をできるようにするという方法だ。
リストを渡したり、禁止事項を論理的に指定する従来の方法は、いわば厳密な正しさを求める功利主義や義務論的なアプローチだったと言えるだろう。稲村が推測するように、それらは「個々の人が個々の状況に応じて自ら考えて方針を決めることを促すような」方法ではなかったため、徳倫理的なアプローチが必要だったというわけだ。
ここまで触れてきたように、AI による人類滅亡のシナリオは、初めから議論の中心を占めていたわけではない。ユドコウスキーやボストロムらがインターネットの片隅で語り始めた言説は、20年以上をかけて業界の議論に浸透してきた。そして、AI の進化に伴い、その危険性(悪用やアライメントの失敗)を気にかけて、どのように制御するかという研究も進展している。
彼らは、単に学術的な興味関心だけで AI の制御に取り組んでいるわけではない。そうした滅亡を防ごうとする取り組みは、哲学的な思想に支えられてもいる。なぜ、彼らはそこまでして人類の命運を気にかける仕事を自らに課しているのだろうか。次回の記事では、この疑問に答えつつ、滅亡論への批判を見ていこう。







 yu
yu




















{kind=link}
{kind=link}